I S K O
Encyclopedia of Knowledge Organization
Thesaurus (for information retrieval)
by Stella G. Dextre ClarkeTable of contents:
1. Introduction and clarification of scope
2. What is a thesaurus?
2.1 Purpose
2.2 Content and structure
2.3 Definitions
2.4 Why the confusion?
3. How a thesaurus is used
3.1 For post-coordinate indexing and searching
3.2 Networked uses, especially in the Semantic Web
3.3 Other uses
4. History of thesaurus development and use
4.1 Origins
4.2 Period of ascendancy
4.3 Systematization
4.4 Maturity, senescence or rejuvenation?
5. Types and styles of thesaurus
5.1 Overview
5.2 The bare minimum
5.3 Different styles for different communities
5.4 Electronic thesauri
5.5 Multilingual vs monolingual thesauri
5.6 Macro- and micro-thesauri
5.7 The search thesaurus
6. Performance and evaluation
7. The future of thesauri
8. Further reading
Endnotes
References
ColophonAbstract:
In the post-war period before computers were readily available, urgent demand for scientific and industrial development stimulated Research and Development (R&D) that led to the birth of the information retrieval thesaurus. This article traces the early history, speciation and progressive improvement of the thesaurus to reach the state now conveyed by guidelines in international and national standards. Despite doubts about the effectiveness of the thesaurus throughout this period, and notwithstanding the dominance of Google and other search engines in the information retrieval (IR) scene today, the thesaurus still plays a complementary part in the organization of knowledge and information resources. Success today depends on interoperability, and is opening up opportunities in Linked Data applications. At the same time the IR demand from workers in the Knowledge Society drives interest in hybrid forms of KOS that may pool the genes of thesauri with those of ontologies and classification schemes.
1. Introduction and clarification of scope
This article is about thesauri intended for use in information retrieval (IR) [1], rather than literary thesauri, which are generally designed for the different purpose of helping and inspiring the choice of words and phrases in normal discourse. The first edition of Roget's Thesaurus, that very well known literary thesaurus, came out long before the first IR thesaurus and probably inspired the invention of the latter. For this reason there is some reference to literary thesauri in the History section of this article. In other sections, however, the term thesaurus invariably refers to the information retrieval thesaurus.
2. What is a thesaurus?
2.1 Purpose
The prime function of a thesaurus is to support information retrieval by guiding the choice of terms for indexing and searching. According to ISO 25964-1 (International Organization for Standardization 2011, Clause 4.1):
The traditional aim of a thesaurus is to guide the indexer and the searcher to choose the same term for the same concept [...] a thesaurus should first list all the concepts that might be useful for retrieval purposes in a given domain. The concepts are represented by terms, and for each concept, one of the possible representations is selected as the preferred term [...] Secondly, a thesaurus should present the preferred terms in such a way that people will easily identify the one(s) they need. This is achieved by establishing relationships between terms — and/or between concepts — and using the relationships to present the terms in a structured display.
Foskett (1980) lists seven purposes for a thesaurus, of which six could be considered subdivisions or sub-aspects of the main purpose cited above. (As for his seventh purpose, a means of standardizing the use of terms in a given subject field, Foskett acknowledges that this is desirable rather than realistic.) While the ISO 25964 description dates from 2011, it follows principles established long before. For example Lancaster (1972, 25) explains:
Schultz (1967) has distinguished the functions of the information retrieval thesaurus from a thesaurus of the Roget type as follows. Roget's purpose was to give an author a choice of alternative words to express one concept; to display a set of words of similar meanings to allow an author to choose one that best suits his need. The information retrieval thesaurus tends to be more prescriptive. The thesaurus compiler chooses one term from among several possible, and directs the user to employ this one by means of references from synonyms and other alternative forms.
The use of preferred terms rather than language-independent codes or character strings is a key feature distinguishing the thesaurus from the classification schemes that were commonly used for IR before the advent of the thesaurus. Retrieval may seem simpler, to the layman, if it can be expressed in words rather than codes. But there is an ambiguity challenge to overcome — in the language of normal discourse one concept can be expressed in many different ways, and conversely one term can have many different meanings. To achieve the aim of always choosing the same term for the same concept an artificial indexing language has to be established, in which synonyms are controlled, homographs are disentangled, and each preferred term is allowed only one meaning (although some may have very broad meanings). The thesaurus conveys that artificial language.
This modus operandi for the thesaurus became established in the 1960s. The computer was then in its infancy: small, primitive, and almost entirely unavailable to the communities of researchers and practitioners needing to retrieve information. Without computers to help, trained human intermediaries were needed at two critical stages of the best IR systems: to index and/or → classify the source documents, and (in the second stage) to perform searches of the same.
Several classic texts of this period, such as Gilchrist (1971), Lancaster (1972), Aitchison and Gilchrist (1972), and Soergel (1974), make it clear that the thesaurus is just one component in the whole IR system comprising a set of tools and procedures, all of which have to be designed in harmony. In those days the IR system typically operated in isolation. While modern technology enables many more possibilities, needing even greater attention to compatibility among system components, today's standards still respect and support the original design principles.
2.2 Content and structure
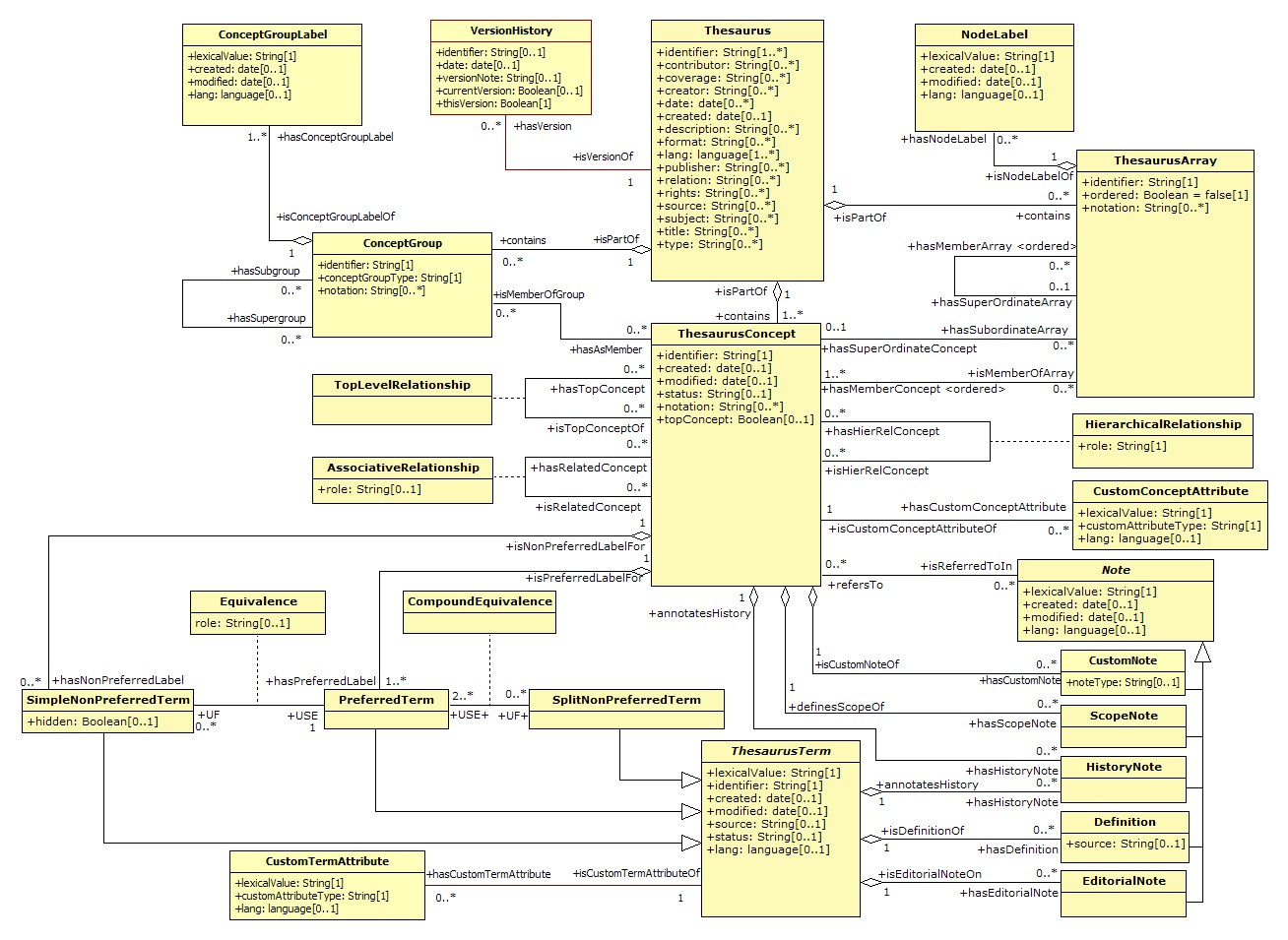
The components of a thesaurus are most succinctly laid out in the UML (Unified Modelling Language) model shown in ISO 25964-1 and reproduced as Figure 1 below. (The model may also be seen on the official website at www.niso.org/schemas/iso25964/ and downloaded from http://www.niso.org/schemas/iso25964/Model_2011-06-02.jpg. Key features are explained in Will (2012).)
{kind=link}

Thus the essential core of a thesaurus is a collection of concepts represented by terms and interlinked by relationships, of which the three main types are equivalence (between terms), hierarchical (between concepts) and associative (also between concepts). By long established convention, the tags USE and UF (Use For) precede preferred and non-preferred terms respectively, and the equally characteristic tags BT, NT and RT indicate broader, narrower and associatively related concepts respectively. Figure 2 illustrates how these simple elements are traditionally displayed. A great many in-house thesauri are built in this minimal way, without calling upon the many optional extras provided for in the data model. The alphabetical display in Figure 2 may optionally be supplemented by other types of presentation, as discussed in section 4.3 below on "Systematization".

The thesaurus can also be visualized as a complex web of interlinked concepts, in which each concept is labelled by one or more terms, in one or more languages. It has these main features:
- The semantic scope of a concept is indicated partly by the totality of terms labelling it, partly by the hierarchical relationships linking it to broader and/or narrower concepts, and where this is not enough, by a scope note and sometimes term definitions
- Admissible hierarchical relationships are of three types: generic, instantial or partitive (subject to some restrictions on the eligible types of partitive link). It is optionally possible to distinguish these types, using the tags
BTG/NTG,BTI/NTI,BTP/NTPrespectively - Admissible associative relationships apply to non-hierarchical situations wherever two concepts are so associated that an indexer or a searcher should consider using one of them as well as, or instead of, the other
- Concepts may be presented and ordered in arrays with node labels, following the principles of facet analysis
- Concepts may also be grouped in loose structures to suit particular domains or applications
- Concepts not explicitly included in the thesaurus may be represented by combinations of preferred terms (in situations known as "compound equivalence" — for example:
coal mining USE coal + mining) - It is also possible to add metadata to terms, to concepts, to relationships and to the thesaurus as a whole, such as dates of introduction or change, version history, housekeeping data, copyright information, etc.
It should be stressed that many of these features are optional, enabling a variety of sophisticated uses, and should not deter straightforward use of the basics in simple applications. Detailed advice on all of them may be found in national and international standards — principally ISO 25964 and ANSI/NISO Z39.19 (National Information Standards Organization 2005) — and are further explicated in Aitchison et al. (2000), Broughton (2006a) and Will (2012).
Despite availability of the guidance cited above, few current or past thesauri comply with the standards in every detail. Difficulties and divergences commonly occur in the following aspects:
- Rigorous conformity with guidelines for hierarchical relationships
- Rigorous facet analysis
- In a multilingual thesaurus, when and how to establish equivalence across languages
- When and how to admit complex concepts designated by compound terms
- Adoption of the data model
Surmounting such difficulties demands considerable expertise and time, adding to the expense of thesaurus construction and to doubts about cost-effectiveness, as noted in Sections 4.4 and 6 below.
2.3 Definitions
An authoritative definition of thesaurus may be found in the international standard ISO 25964-1 (Clause 2.62):
controlled and structured vocabulary in which concepts are represented by terms, organized so that relationships between concepts are made explicit, and preferred terms are accompanied by lead-in entries for synonyms or quasi-synonyms.
Although phrased differently, a broadly compatible definition is that in the American standard ANSI/NISO Z39.19-2005 (R2010) (National Information Standards Organization 2005, Clause 4.1):
A controlled vocabulary arranged in a known order and structured so that the various relationships among terms are displayed clearly and identified by standardized relationship indicators. Relationship indicators should be employed reciprocally.
The above definitions derive their authority from the process of drafting and approving a standard, which requires agreement by a committee of experts and extensive consultation among the user community. But copious alternative definitions exist in a variety of texts, illustrating the extent of confusion that surrounds the thesaurus. Many are intended to counteract loose use of the term thesaurus, which is commonly applied to any sort of → knowledge organization system (KOS), such as a subject headings list, or to a set of synonym rings. Conversely, some vocabularies that could properly be described as thesauri may instead be called an "ontology", or a "taxonomy".
2.4 Why the confusion?
Some of the current confusion may be explained by developments that emulate thesaural conventions in other types of KOS. In the 1990s, for example, a "thesaurification" project explored adaptation of some schedules of the UDC (Universal Decimal Classification) (Riesthuis and Bliedung 1991). This did not interfere with the primary function of the UDC as a classification scheme. Around the same time the Library of Congress Subject Headings (LCSH) began to adopt thesaurus tags such as BT, NT and RT in its display. (Thesaural use of these tags is illustrated in Figure 2.) Today (3 August 2016) a Wikipedia entry for the LCSH claims that "The Library of Congress Subject Headings (LCSH) comprise a thesaurus [...] of subject headings, maintained by the United States Library of Congress, for use in bibliographic records." The use of thesaural conventions and BT/NT tags, however, does not make the LCSH a thesaurus, as pointed out long ago by Rolland-Thomas (1993) and illustrated more recently by Spero (2008; 2012). The LCSH is fundamentally a subject headings list (defined as a "structured vocabulary comprising terms available for subject indexing, plus rules for combining them into pre-coordinated strings of terms where necessary" — ISO 25964, clause 2.57) rather than a thesaurus. Differences between the way subject headings and thesauri are used are discussed in De Keyser (2012).
Another explanation is that all the national and international standards for thesauri take the form of guidelines rather than mandatory instructions. Adopters therefore have a great deal of liberty to cherry-pick only the recommendations that suit the circumstances of their own thesaurus and ignore the rest.
A third part of the explanation is that very often the person charged with sorting out an organization's information assets has little or no training in knowledge organization. If the decision is to develop an in-house indexing language or a filing structure, it may be built in whatever way comes easiest, and randomly named a "classification scheme" or a "thesaurus" or an "ontology" to suit the fashion of the day. The misnomer thesaurus has spread easily this way, leading to much confusion.
Even for the trained information professional, distinguishing between the different types of KOS can be hard. Over the years many attempts at clarification have been made (e.g. Fast et al. 2002; Garshol 2004; Hodge 2000; Kless et al. 2012). Useful definitions of several KOS types may be found in ANSI/NISO Z39.19 and ISO 25964; ISO 25964-2 (International Organization for Standardization 2013) also brings out the similarities and the differences to provide for in the context of → interoperability. Zeng (2008) casts further light by analysing and comparing features of many different types of KOS.
A different sort of confusion surrounds the basic roles of terms versus concepts. From the early days of thesaurus R&D, the basic aim was to index the semantic content of documents rather than the terminological content. Concepts useful for indexing were collected in a thesaurus, where they were organized and their inter-relationships were established. When a hierarchical relationship was established, the reciprocal links between the broader and narrower concepts might usefully have been designated BC (Broader Concept) and NC (Narrower Concept). In practice, however, they were named BT (Broader Term) and NT (Narrower Term), and this practice was adopted widely. The I974 edition of ISO 2788 (International Organization for Standardization 1974) attempted to clarify by explaining "the hierarchical relation is represented by the references BROADER TERM (BT), representing the relation of a concept being superordinated, and NARROWER TERM (NT), indicating the reciprocal relation" (clause 3.4.3). But it was too late — the misnomers have stuck, to this day.
Over the decades this confusion has led to much misunderstanding among thesaurus users. Also the software developed for thesaurus management has often adopted a data model in which the hierarchical and associative relationships are established between terms rather than between concepts, and this has impeded thesaurus interoperability. See discussion in Dextre Clarke and Zeng (2012).
3. How a thesaurus is used
3.1 For post-coordinate indexing and searching
The original thesaurus purpose and mode of use as declared in the standards is confirmed in many texts, such as Wellisch (1995, 475) "thesauri are primarily intended for indexing as well as for searching and retrieval from post-coordinated systems, in which an indexer may assign several descriptors to documents, while users may combine those descriptors to form search statements". For more background on post-coordinated systems and their underpinning with controlled vocabularies and → Boolean logic, see Sharp (1967), Lancaster (1972) or Dextre Clarke (2008). Today's continuing demand for quality bibliographic databases supporting Boolean retrieval is upheld by Hjørland (2015).
As originally conceived, the act of consulting the thesaurus either for indexing or for searching can be time-consuming. When the user has worked out key concepts of the document to be indexed or the query to be investigated, he or she needs to find an entry point among the terms and/or groups available, and follow the network of relationships to establish the closest possible match in the thesaurus. Skill as well as patience and subject knowledge are needed, since thesauri vary greatly in quality and in format (See Section 5 below). Nowadays it is hard to find indexers with the requisite training, while trained end-users are very rare indeed. Therefore modern systems tend to automate both indexing and searching, using an electronic version of the thesaurus.
Thesaurus-based indexing functions may be needed in situations such as library cataloguing, compilation of bibliographic databases, and tagging/indexing of image collections. Generally a software package designed for that application is used, with indexing support capabilities that vary from (at the simple end) speeding up the task of thesaurus navigation to (at the sophisticated end) delivering totally automatic indexing. In between are systems that validate and/or switch the indexer's terms, that select candidate terms for the human indexer to accept or reject, and "suggester" systems for social tagging.
Forty years ago Caplan (1978) reported a number of failures in trials of thesaurus-based automatic indexing. More recently Lancaster (1998) provided a more promising account of the techniques available, but concluded (p. 294) "even the most sophisticated of current automatic indexing procedures compare unfavourably with skilled human indexing". Eight years later Tudhope et al. (2006) were still calling for more research. Ten years later, research into metadata enrichment with thesaurus terms was outlined in Tudhope and Binding (2016). Kempf and Neubert (2016) describe several modes of implementation, including one that exploits inter-KOS mappings. Clause 16 of ISO 25964-1 advises on the thesaurus features needed to enable such functions.
Meantime, as described in Section 7 below, a new breed of KOS is emerging in the enterprise search sector, loosely named "taxonomy", and stimulating a demand for automatic categorization tools. Since some taxonomies share some features with thesauri (See ISO 25964-2, clause 19), the associated R&D effort is already yielding progress that can be applied to thesaurus-based indexing. Unfortunately a great many in-house applications go unreported in the research literature, including research by the vendors of software for automatic categorization. In the experience of this author, the support for thesaurus-based indexing in off-the-shelf library management packages is rarely as effective or user-friendly as it could be. Likewise the quality of automatic or semi-automated indexing tools varies greatly and much care is needed to obtain reliable outputs. Further discussion of automatic indexing is outside the scope of this article, particularly since most cases do not use a thesaurus.
Turning now to search applications, here too the electronic medium speeds up thesaurus navigation. Furthermore, with suitable software it enables broadening or narrowing a search at will. Consider, for example, a search for "packaging AND fruit". Relevant results would include any items dealing with the packaging of any of potentially hundreds of different types of fruit. The technique known as search explosion exploits the hierarchical relationships in a thesaurus to expand the search statement automatically and cover all those hundreds of fruit types. It is similarly possible to extend a search via associative relationships, and this is usually termed search expansion. These and other search functions are reviewed in Shiri et al. (2002), and further discussed in Shiri (2012). The case study of the STW Thesaurus for Economics by Kempf and Neubert (2016) illustrates similar techniques, and other ways in which a thesaurus can be used to enhance retrieval, even when the user is unaware of its support.
Evidently indexing and searching have moved on from the early days, when a thesaurus and its IR system could operate usefully in isolation, and even without a computer. Thesaurus use in today's IR applications relies on electronic manipulation, involving transfer of data from one subsystem to another. Success depends on interoperability, i.e. the ability of systems and/or components to exchange information and to use the information that has been exchanged. There are now at least two main contexts for thesaurus interoperability:
- "Vertical integration" of the thesaurus with software for indexing or searching or occasionally some other IR function, as already described;
- "Horizontal engagement" of the thesaurus with another KOS (perhaps another thesaurus, or a subject headings list, or a classification scheme), typically requiring conversion of indexing and search expressions between the languages of the different KOSs.
The vertical context sees a thesaurus transformed from a static map of concepts, terms and relationships to a functioning system. The horizontal context crosses a different boundary, to be described next.
3.2 Networked uses, especially in the Semantic Web
A single search across multiple databases would be relatively straightforward if all used the same natural language, the same machine protocols, and the same indexing language. To overcome the disparities found in real life, two approaches to interoperability are especially relevant for KOSs, namely inter-vocabulary mappings and Linked Data.
A mapping is defined as a "relationship between a concept in one vocabulary and one or more concepts in another" (ISO 25964-2, clause 3.41). For example, an equivalence mapping between the concepts labelled instant coffee in one thesaurus and soluble coffee in another, would establish that they are viewed as identical for semantic purposes. Existence of mappings like this makes it easy to "translate" search queries for use in the corresponding IR systems, and/or to augment the metadata of resources indexed with either thesaurus. When sets of mappings are available between many KOSs, it opens the prospect of extending searches widely and multilingually.
The value of such mappings is demonstrated in the "Metathesaurus" of the Unified Medical Language System (UMLS) <www.nlm.nih.gov/research/umls/>, a semantic tool serving research in biomedicine, health care and related fields. It contains concepts from more than 100 KOSs as well as relationships from within the KOSs and many mappings between their respective concepts. Andrade and Lopes Gines de Lara (2016) assess its usefulness in retrieval from relevant databases. The influence of this construct has led some authors to speak of a metathesaurus wherever existing thesauri are integrated, linked or mapped together (Shiri 2012) — and a variety of ways is possible.
Not all mappings are as simple as equivalence. Dextre Clarke (2011a) enumerates a variety of mapping types investigated in research projects such as Renardus, MACS (Multilingual ACcess to Subjects), CrissCross and KoMoHe. ISO 25964-2 (International Organization for Standardization 2013) provides for hierarchical and associative mappings as well as equivalence. Hierarchical mappings are directional — either broader or narrower. Equivalence mappings subdivide into simple or compound; compound equivalence has two subtypes (intersecting or cumulative) while simple equivalence can be qualified as exact or inexact. Figure 3 shows the range of mapping types, with an example of each. Mapping statements should be expressed using the conventional tags (EQ, BM, NM etc.) and the symbols shown.

Even more subtlety is possible in applications that need to distinguish between subtypes of hierarchical mapping. See Figure 4.

While thesaurus mapping projects have a much longer history (see, for example, Horsnell 1975 or Hood and Eberman 1990, or Hoppe 1996 reporting on UMLS work that began in 1986), the growth of the Internet and the WWW has made them more widely applicable. Thus Zeng and Chan (2004) drew attention to opportunities emerging in the Internet context and Vizine-Goetz et al. (2004) described a labour-saving methodology. Mayr and Petras (2008) illustrated the possibilities. Several other mapping projects were reported in Proceedings of the Cologne Conference on Interoperability and Semantics in Knowledge Organization (Boteram et al. 2011).
Doerr (2000) analysed perceived semantic problems of thesaurus mapping. Confusingly for us today, his use of the term mapping differs from the ISO 25964 definition, applying to relationships within one vocabulary rather than between different ones. Thus he deplored the weakness of thesaurus semantics for hierarchical relationships when compared with class subsumption in an ontology. Subsequent release of SKOS [2] seems to have overcome or at least eased such problems (Tudhope and Binding 2016). According to Isaac and Baker (2015, 2)
The lack of a way to express less formal semantics hindered many early projects that tried to apply Semantic Web technology in the cultural sector by massaging existing knowledge organization systems into formal ontologies. Given the scope of the artifacts considered, this effort required considerable ontological debugging that was ultimately of dubious value. Indeed, most information retrieval scenarios using KOS for searching or browsing collections do not require more than the information that one concept is broader than another.
Establishment of the World Wide Web (WWW) has brought new opportunities and challenges for IR in general, and for KOS use in particular. On the one hand, vast resources have come within our reach; on the other hand, individual resources may be expressed in a multiplicity of languages, like the Tower of Babel. As pointed out in the context of the STW Thesaurus for Economics, "The Web changes everything" (Kempf and Neubert 2016, 162).
A particular breakthrough for KOS linkage was approval and release of the W3C recommendation SKOS Reference (Miles and Bechhofer 2009), with specific guidance on how to publish mappings between KOSs. SKOS publication followed on from a research report by Miles (2006, 1) aiming "to develop a formal theory of retrieval using controlled vocabularies that have a simple and intuitive structure [such as thesauri, classification schemes, subject heading systems, taxonomies and other types of structured vocabulary], to provide the necessary theoretical foundations for the development of Semantic Web languages and design patterns for distributed retrieval applications". Since 2009 a number of extensions have been added to SKOS to support interoperability in particular contexts; work on some mapping tools for thesauri is described in Endnote 2.
Turning to the other main interoperability opportunity, the principles of Linked Data are set out in Tim Berners-Lee's 2006 paper at www.w3.org/DesignIssues/LinkedData.html. As he explains (p. 1), "The Semantic Web [...] is about making links, so that a person or machine can explore the web of data. With linked data, when you have some of it, you can find other, related, data. Like the web of hypertext, the web of data is constructed with documents on the web. However, unlike the web of hypertext, where links are relationships anchors in hypertext documents written in HTML, for data they links [sic] between arbitrary things described by RDF". For a KOS (such as a classification scheme or a thesaurus) the essential starting point is to publish the whole scheme on the Web using Resource Description Framework (RDF) syntax and giving each concept or class a Uniform Resource Identifier (URI). Once that is in place, anyone anywhere can set up a direct link to any concept or class. For example, if a web page or a bibliographic record in a database on the Web has been indexed with the thesaurus concept renewable energy, the person interested in that concept can move directly from the thesaurus to those and other relevant pages. This opens up the prospect for any thesaurus published on the Web to act as a connecting hub for an immense literature in the subject field concerned, without any need to assemble the disparate documents in one collection or database. See Endnote 2 re tools for hand-in-hand application of ISO 25964 and SKOS.
A vision of Wikipedia as the connecting linked data hub for hundreds of thesauri and other KOSs is outlined in a speculative paper from Garcia-Marco (2016). Kempf and Neubert (2016) show how the use of Linked Open Data (LOD) is already paying off for the STW Thesaurus for Economics. Baca and Gill (2015) describe the challenges and long development path at the Getty Research Institute leading up to publication on the Web of three KOSs that are very influential and widely used in the cultural heritage sector: The Art & Architecture Thesaurus, the Union List of Artist Names and the Getty Thesaurus of Geographic Names. They hope thereby to enable potential universal access to information in different formats and languages, about the works of art and countless other exhibits in museums, libraries and galleries around the world. The 2017 release by the European Commission of a new European Interoperability Framework (EIF) <ec.europa.eu/isa2/eif> further emphasizes the opportunities for public administrations to put linked data to work across the countries of Europe.
3.3 Other uses
Although not the primary purpose, thesauri may also be used for precoordinate indexing (Wellisch 1995; International Organization for Standardization 1996). When this is done, users of the precoordinate index (typically found at the back of a book) are not expected to consult a thesaurus (since cross-references to synonyms etc. may be embedded within the index).
Conversely, a thesaurus may be used not for indexing but only for searching. This removes the need for compliance with the standards. See Section 5.7 below.
Educationalists sometimes argue that a thesaurus is valuable in its own right, for → domain analysis, as a conceptual and terminological guide to a domain, and for development of the mind. Lykke Nielsen (2001, 778) states that "the thesaurus is a tool that helps individual users to get an understanding of the collective knowledge domain". Broughton (www.iskouk.org/sites/default/files/ISKOUKGreatDebate-Broughton_0.pptx, slide 6) argues "the thesaurus teaches us to take a critical and analytical approach to the domain. It makes us think about the nature of concepts, the form of their labels [and about] their relationships" and (slide 9) "there's something fundamental about this approach to modelling information domains that should not be lightly abandoned". More generally Soergel (2014) has argued that the construction of any sort of knowledge organization schema, particularly with entity-relationship modelling, facet analysis and a graphical presentation of concepts, is a useful learning discipline.
Still more uses are emerging as the Internet pervades the office and everyday living. To satisfy these new uses, however, the standard thesaurus model may need to evolve.
4. History of thesaurus development and use
4.1 Origins
To Peter Mark Roget, working in the middle of the 19th century, we owe the insight that it would be valuable to supply "a collection of the words [the English language] contains and of the idiomatic combinations peculiar to it, arranged, not in alphabetical order, as they are in a dictionary, but according to the ideas which they express" (Roget 1952, 559). His aim, rather than information retrieval, was to help "find the word, or words, by which [an] idea may be most fitly and aptly expressed" (ibid., 559).
An expanding volume of scientific and other scholarly literature in the first half of the twentieth century brought challenges for → classification, the orthodox retrieval technology of the times. It led to developments such as faceted classification, post-coordinate indexing, and experiment with various sorts of cards, all of which were to prove helpful when the idea of an IR thesaurus was conceived.
According to Roberts (1984) the first suggestion of using a thesaurus in the context of IR came from Calvin Mooers in 1947. At around the same time C.L. Bernier and E.J. Crane made a similar, independent suggestion, but "expressed the view that a general thesaurus was not an appropriate form for retrieval purposes" (Roberts 1984, 272). Much experiment followed over the next decade, but none of the various thesaurus approaches described by Joyce and Needham (1958) — e.g. "term lattices" — seems to have prospered, nor come close to the style of thesaurus that was to emerge in 1959. It was after this gestation period that "the first full-scale, operational in-house retrieval thesaurus [was produced] to solve pressing practical problems at E.I. Du Pont Nemours and Co., Inc., Wilmington, U.S.A." (Roberts 1984, 281). Krooks and Lancaster (1993) credit Eugene Wall with developing the principles that determined the shape of this pioneering compilation.
4.2 Period of ascendancy
More research and development (R&D) followed the 1959 birth of the IR thesaurus, one of the driving forces being the post-war preoccupation of the US military with a need for effective information management. Progress came with publication of the Thesaurus of ASTIA Descriptors (Armed Services Technical Information Agency 1960) and of the Chemical Engineering Thesaurus (American Institute of Chemical Engineers 1961), followed in 1967 by the landmark Thesaurus of Engineering and Scientific Terms (Office of Naval Research 1967), commonly known as TEST. A fuller description of these works can be found in Krooks and Lancaster (1993), and in Aitchison and Dextre Clarke (2004).
Widespread use of thesauri continued throughout the 1960s, 1970s and 1980s, in IR systems that mostly relied on cards of various types, sizes and materials, including some that were sorted by machines (Dextre Clarke 2008; Sharp 1967). These were post-coordinate systems, which require each document to be indexed by selecting relevant terms from a controlled vocabulary such as a thesaurus. A thesaurus was used too by many of the bibliographic databases that were hosted online by services such as Lockheed's Dialog system, followed later by CD-ROM distribution. Notable pioneers of construction methodology included Jean Viet, Jean Aitchison and Donald Leatherdale, who each produced a number of influential thesauri. Dextre Clarke (2008) provides a vivid account of how the tools and technology of those times were used.
Further impetus came from development of national and international standards for thesaurus construction, indicating the extent of interest from the information-using community. The most influential, listed in chronological order of their first editions, included:
- Deutsches Institut für Normung. DIN 1463 Guidelines for the establishment and development of monolingual thesauri [translated title] 1972 (now withdrawn, with ISO 25964-1 recommended in its place)
- International Organization for Standardization. ISO 2788-1974 Documentation - Guidelines for the establishment and development of monolingual thesauri. 1st ed. International Organization for Standardization: Geneva, 1974 (now superseded by ISO 25964-1)
- American National Standards Institute. ANSI Z39.19-1974 American National Standard Guidelines for thesaurus structure, construction and use. American National Standards Institute: New York, 1974 (now superseded by ANSI/NISO Z39.19-2005)
- International Organization for Standardization. ISO 5964-1985. Documentation - Guidelines for the establishment and development of multilingual thesauri. International Organization for Standardization: Geneva, 1985 (now superseded by ISO 25964-1)
These and other KOS standards are discussed in Dextre Clarke (2011b), although this article pre-dates publication of the two parts of ISO 25964, in 2011 and 2013 respectively (International Organization for Standards 2011; 2013).
4.3 Systematization
As noted by Dextre Clarke (2001, 86) "standardisation has not brought uniformity". Having the status of guidelines rather than mandatory requirements, all the standards left plenty of scope for continuing experiment. While nearly all published thesauri include an alphabetical list of terms (which may be as simple as the extract in Figure 2, or can show additional attributes and relationships) very often the alphabetical list is complemented by other types of display.
The great weakness of any alphabetical list is the need to know a term before one can find the corresponding concept(s). Thus an alphabetical list does not respect Roget's vision that it would be useful to arrange terms systematically according to the ideas or concepts they represent. His literary insight applies equally in the context of information retrieval. A search concerning wood for example, could equally be expressed using the term timber, and an alphabetical list would place these terms far apart even though the underlying concept may well be the same.
The classic TEST thesaurus addressed this weakness by providing three Indexes: permuted, hierarchical and by subject category. A derived style, slightly more elaborate, was followed in several thesauri designed by Jean Viet, including the influential Macrothesaurus from the Organization for Economic Cooperation and Development (OECD). A different approach was adopted by Aitchison, Gomersall and Ireland in their ground-breaking 1969 vocabulary Thesaurofacet, comprising a faceted classification fully integrated with a thesaurus. This approach relies on concept-based analysis from the very start, enabling elaboration of the faceted classification and subsequent derivation of a thesaurus. Aitchison and Dextre Clarke (2004) describe how Aitchison progressively refined and enhanced this technique over the decades to follow, designing a long line of thesauri such as the UNESCO Thesaurus (Aitchison 1977), the BSI ROOT Thesaurus (British Standards Institution 1981), and the International thesaurus of refugee terms (Aitchison 1996). Biswas and Smith (1989) review a number of other efforts to combine a classification scheme with a thesaurus, especially the "Classaurus" and its variants developed in India by Bhattacharyya, Devadason and others. Broughton (2006a) also advocates facet analysis as the soundest basis for thesaurus construction, and claims that "the generation of a thesaurus from its equivalent faceted classification is almost as automatic a process as thesaurus construction can ever hope to be" (Broughton 2006b, 60).
Rather than a full-blooded classification, the systematic listing of preferred terms in MeSH (Medical Subject Headings) was a set of extensive hierarchical "Tree Structures" with an elaborate expressive notation that served both as a vocabulary look-up device and as a search key in the databases of MEDLARS (Medical Literature Analysis and Retrieval System) and later Medline. The first (1982) edition of the multilingual thesaurus AGROVOC (Leatherdale 1982), taking a different approach, avoided the need for a separate hierarchical section by embedding the complete upper and lower hierarchical context of each concept within the alphabetical display. See Figure 5.

Throughout the 1960s, 1970s and 1980s much of the experiment was constrained by the need to provide users with printed copies of the thesaurus, and update them regularly. Even after bibliographic databases such as Medline and AGRIS became available online through host services such as Dialog, or on CD-ROM discs, the corresponding thesauri were still widely distributed in hard copy. As late as 1990 the first edition of the influential Art & Architecture Thesaurus was published conventionally, and even followed in 1994 by a second edition (Getty Art History Information Program 1994) in 5 weighty volumes, each over 500 pages. But after that only the electronic version has been maintained. From the 1990s onwards, most new thesauri have been published in electronic media only.
If the focus is on an electronic version, not only are the costs and hassle of printed distribution eliminated, but also there is greater freedom to change the presentation frequently in response to feedback, and develop features that support indexing and searching of any associated databases. For example the STW Thesaurus for Economics is nowadays published on the Web (see zbw.eu/stw/version/latest/about.en.html), enabling immediate searching of the EconBiz database and at the same time supporting Linked Open Data applications. Similarly AGROVOC has in the twenty-first century undergone huge redevelopment, exploiting SKOS to enable Linked Data applications and incorporating some new relationship types in its "agrontology" (Caracciolo and Keizer 2014). Figure 6 shows how an entry in AGROVOC looks in 2017, with simultaneous views of hierarchy and all the language equivalents, etc., on one screen, plus easy hyperlinks to all related concepts.

horses in AGROVOC, January 20174.4 Maturity, senescence or rejuvenation?
A tailing-off in the popularity of thesauri has occurred from approximately the end of the 1980s, probably due to increasing availability of desktop computers, as well as the rise of the Internet (Dextre Clarke 2008). The new technologies have enabled alternative retrieval methods that for most applications appear less expensive than post-coordinate indexing plus thesaurus development and maintenance. From that time onwards, while a good thesaurus works no less effectively than before, its role has been relegated to relatively fewer search applications (Dextre Clarke 2016), such as retrieval from image collections (MacFarlane 2016), cultural heritage collections and bibliographic databases. In these situations it still brings benefits, especially when implemented in linked data mode (Tudhope and Binding 2016). Shiri (2012) paints an optimistic picture of the opportunities.
Latest versions of the standards Z39-19, ISO 25964-1 and ISO 25964-2 are dated 2005 (reaffirmed 2010), 2011 (confirmed 2017) and 2013 respectively. While in them the basic principles of thesaurus design show little change from previous versions, it's clear the context in which a thesaurus operates has changed markedly. Interoperability is now the key to success — and is reflected in the content of the standards. See Endnote 3 for some clarification of the differences between these standards.
Some authors believe the way relationships are treated in a thesaurus could usefully evolve. Alexiev et al. (2014) suggest that interoperability, inferencing capabilities and the reliability of search explosion would all be improved by more rigorous discrimination between the three types of hierarchical relationship allowed by the standards. Hjørland (2016) asks why thesauri "bundle" different kinds of semantic relations into one relationship type — the associative — and suggests that "thesauri would probably be improved" if they adopted some attributes from ontologies, in particular the avoidance of "standardized limitations on the kind of semantic relations used" (p. 151). He points out further that the most useful types of relationship to specify may vary from one domain to another. Vernau <http://www.iskouk.org/sites/default/files/190215Debate_1-JudiVernau.mp3> too has called for changes in the approach to relationships.
Enthusiasts for change may like to note that the current standards are already permissive of developments e.g. the inclusion of new customized relationships, that do not transgress the existing rules. All international standards are reviewed on a five-year cycle, enabling proponents to make the case for revision as soon as such developments have proved their worth.
The passage of time will tell whether the thesaurus continues as before in its relatively few niche applications, or whether it blossoms into new networked opportunities, perhaps revitalised by an infusion of ideas from ontologies and other types of KOS. Section 7 below summarizes the challenges and opportunities for continuing exploitation and evolution.
5. Types and styles of thesaurus
5.1 Overview
The Basel Register of Thesauri, Ontologies & Classifications (BARTOC) <bartoc.org> and the Taxonomy Warehouse <taxonomywarehouse.com> list hundreds of thesauri among other types of KOS. Despite their astonishing variability in aspects such as subject scope, size, specificity, function, format, layout, language, quality of construction, etc., it is hard to divide them into distinct species or types. Much of the variation seems stylistic rather than fundamental, with one style borrowing features from another and a proliferation of hybrids. This section will therefore start by describing the "bare minimum" that can be expected in any IR thesaurus, and continue with some discussion of frequently observed differences in style, before discussing some categories of thesaurus that might or might not be considered distinct types.
5.2 The bare minimum
These features are indispensable in a traditional functioning thesaurus:
- For every concept deemed worth indexing/searching, inclusion of as many as possible of the terms that might represent it, with one of these selected as preferred;
- Any hierarchical or close associative relationships between the concepts should be shown;
- Some kind of display or index must enable users to look up the terms and concepts.
Taken together these three requirements typically lead to a list of all terms and relationships, with entries alphabetically arranged, in the style of the extract in Figure 2. Alongside these traditional requirements it is worth noting a trend towards applications in which the thesaurus is implemented behind the scenes; this reduces or obviates the need for any kind of display, or indeed for designating the preferred term for a concept.
While the vocabulary illustrated in Figure 2 complies with the standards, a more ambitious thesaurus would also incorporate Scope Notes, History Notes, faceted arrays introduced by node labels, concept groups and other optional features. The data model in Figure 1 points to very many opportunities for enhancing a thesaurus in ways that are standards-compliant and supportive of interoperability in networked applications. As to format, the alphabetic list is often supplemented by other displays to help users find the right term, such as a classified display, a set of hierarchical trees, a permuted index, or even a graphical display. Thesauri that were developed to serve a particular database sometimes show extras, such as the number of postings for each term. In lieu of explicit display, some of the extra features may be hidden, invoked only as functions of a retrieval system.
5.3 Different styles for different communities
In this section we discuss presentational differences, which may not be fundamental to thesaurus operation but can still influence user acceptance and hence retrieval effectiveness. In certain domains a particularly influential thesaurus has influenced the development of subsequent vocabularies. For example, MeSH (the Medical Subject Headings list of the National Library Medicine, first issued in 1960) early on developed a set of “Tree Structures” having a distinctive style of notation directly functional in database retrieval (and still visible in today's MeSH online, see https://meshb.nlm.nih.gov/#/treeSearch). Both the trees and the notation were emulated in later thesauri for medical applications, such as EMTREE, the thesaurus of Elsevier's Excerpta Medica database. Similarly the Art & Architecture Thesaurus first published in 1990, with a very distinctive style of facet-driven hierarchical display incorporating "guide terms", has inspired much thesaurus development work in the heritage sector worldwide.
Other historical influences have been thesaurus maintenance software and preferences of the original designers. Thus thesauri managed with the CAIRS or the TIKIT package characteristically presented "Stop terms" and "Go terms", and some user communities still look for these in every new thesaurus. Many thesauri funded in the twentieth century by the Commission of the European Communities used the ASTUTE software, which generated alphabetical displays with entries in the style of Figure 5. The style and conceptual approach of pioneers Jean Viet and Jean Aitchison (see 4.3 above) inspired many followers to apply the principles of classification to thesaurus development.
A good many other variations on format and layout of printed thesauri, including some graphical representations, are described and/or illustrated in Foskett (1980). Shiri (2012) provides an update, including screen layouts for electronic thesauri, to be discussed next.
5.4 Electronic thesauri
Arguably an electronic format is just another stylistic variation, not affecting the fundamentals. Electronic thesauri have been around from the early days of online bibliographic databases such as AGRIS, CAB Abstracts, INSPEC, Engineering Index, ERIC, etc., that chose to provide their search vocabularies as a printed thesaurus and as an electronic version of the same, integrated to greater or lesser degree with the search functions of the database. In such cases the underlying content and structure of both online and printed versions are the same.
That said, the electronic medium offers enhanced opportunities for thesaurus design, maintenance, presentation and implementation, enabling interactive retrieval functions for the users as described in Section 3 above. To exploit linked data and other Semantic Web applications, the electronic thesaurus should be published on the Web in the format of the W3C standard SKOS Simple Knowledge Organization System Reference (see https://www.w3.org/TR/skos-reference/). ISO 25964-2 (International Organization for Standardization 2013) gives further advice on semantic interoperability between thesauri and other KOSs. Shiri (2012) discusses several examples and offers guidelines for the design of thesaurus-enhanced search interfaces.
5.5 Multilingual vs monolingual thesauri
All the stylistic variations described so far can apply to monolingual or to multilingual thesauri. The inclusion of more than one language is not just another variable — it makes a big difference to design, maintenance and use. Compare the illustration in Figure 2 with that in Figure 7, for a bilingual thesaurus (English/Spanish). The display illustrated is for use by speakers of English; an alternative, language-inverted display for speakers of Spanish would show all the terms and relationships for that language.

Multilingual thesauri can be subdivided into two types — symmetrical or not. In a symmetrical thesaurus, every concept has a preferred term in each of the languages, and the scope and relational structure is identical in each. In a non-symmetrical thesaurus not every concept need be represented in all the languages, and the hierarchical structure may vary from one language to another to accommodate cultural differences. See more discussion and examples in Working Group on Guidelines for Multilingual Thesauri of IFLA Classification and Indexing Section (2009) and Hudon (2001).
5.6 Macro- and micro-thesauri
An original aim of the OECD's Macrothesaurus published in 1972 was to "create a documentary language for processing information in the broad field of economic and social development, while striving for compatibility with sectoral thesauri serving agriculture, industry, labour, education, population, science, technology, culture communication, health and the environment" (Viet 1972, v). Both the name and the aim were popular, and so years later the term macrothesaurus with a small m was borrowed as a generic name for any broad-level thesaurus that either contains or is aligned with a number of microthesauri having greater specificity in a more limited field.
The normal situation according to Aitchison et al. (2000, 177) is for built-in compatibility, with the specialized "microthesaurus" being "mapped onto, and entirely integrated within, the hierarchical structure of some broader thesaurus, the macrothesaurus". They acknowledge, however, that sometimes the macrothesaurus is a separate entity, managed independently of any corresponding microthesauri.
In practice it is not easy to maintain alignment between specialized thesauri used by different communities, unless management is centralized. Among the successful examples today is EUROVOC, the Multilingual Thesaurus of the European Union, which is structured into 21 "domains", each of which is subdivided into a number of "microthesauri". Concepts belong to more than one microthesaurus if appropriate. Each microthesaurus contains a hierarchically structured list of concepts, terms and relationships, and can be downloaded separately (see and browse at eurovoc.europa.eu/drupal/).
5.7 The search thesaurus
The search thesaurus is one designed for use, not in indexing, but only at the search stage (see more discussion in Aitchison et al. 2000 and Lykke Nielsen 2004). At first glance this would not seem to make it very different. And indeed, sometimes a normal standards-compliant thesaurus is applied only at the search stage, and then described as a "search thesaurus".
A deeper study, however, reminds us of the way a standard thesaurus is designed to work: "The concepts are represented by terms, and for each concept, one of the possible representations is selected as the preferred term" (ISO 25964-1, clause 4.1). In the case of the thesaurus shown in Figure 2, for example, an indexer would assign the term pigs to every item in the collection that deals with pigs or sows, or hogs, or porkers. The searcher would use only the term pigs to retrieve all these items. But if the same tool was being used as a search thesaurus, indexing would not have taken place. The searcher would have to look for "pigs OR sows OR hogs OR porkers".
Thus the notion of a preferred term is inapplicable to a search thesaurus designed as such. Standards such as ISO 25964 become irrelevant, allowing even greater freedom of content, style and structure. Lopez-Huertas (1997) proposes one example, structured very differently from the standard thesaurus. Another fully worked example is Knapp's The contemporary thesaurus of social science terms and synonyms which attempts to remind readers of many alternative ways of expressing the same idea, using a layout quite different from the standard (see Fig. 8). In practice not many such works have been published.
|
The converse of the search thesaurus is the indexing thesaurus, to be used for indexing and not for search. While applications are sometimes found in which indexing is enhanced automatically with the help of a thesaurus, a standard thesaurus is usually applied, rather than one designed for indexing alone.
6. Performance and evaluation
While the criteria presented by Mader and Haslhofer (2015) apply to a range of KOSs and not specifically thesauri, they do help evaluate interoperability in the context of SKOS use, for any controlled vocabulary. Much earlier, Owens and Cochrane (2004) described four approaches — structural, formative, observational and comparative — to thesaurus evaluation. None of these directly measures the effectiveness with which a thesaurus succeeds in the purpose for which it was intended — retrieving information. Such a measure is difficult if not impossible to devise, partly because the thesaurus is only one of several components in the retrieval system, and partly because there are so many variables in the context of use. Lengthy experiments in the 1960s and 1970s studied the effects on precision and recall as different features of indexing languages were tested, but ultimately failed to provide conclusive support for the use of any controlled vocabulary (Keen 1973; Soergel 1994; Svenonius 1986; Dextre Clarke 2001). Despite efforts over many years, we still do not have definitive proof that development and use of a thesaurus is a worthwhile investment. Dextre Clarke (2016) provides an account of the continuing debate.
The long debate was highlighted at an event run by the UK Chapter of ISKO in February 2015 (see proceedings at www.iskouk.org/content/great-debate), with a subsequent issue of Knowledge Organization (2016) devoted wholly to questioning the future of thesauri. Despite reservations expressed by Hjørland (2016), that depiction of the future makes it clear the context of KOS use is changing, and the thesaurus evolving to occupy new roles and opportunities. Although quantitative proof of efficacy may be lacking, there is plenty of qualitative evidence of thesauri prospering and supporting users in some key areas of a changing environment. Modes of evaluation may have to adapt to reflect the new context.
7. The future of thesauri
The thesaurus as conceived by the current national and international standards is still based on the assumption "that human intellect is usually involved in the selection of indexing terms and in the selection of search terms. If both the indexer and the searcher are guided to choose the same term for the same concept, then relevant documents will be retrieved. This is the main principle underlying thesaurus design" (ISO 25964-1, "Introduction", vi). Nowadays opportunities to apply the thesaurus may shrink because the trained indexer and searcher are increasingly scarce. End-users are largely unaware of thesauri (this is confirmed, for example, by Greenberg 2004); trained indexers and searchers are usually deemed unaffordable. Areas where the thesaurus seems most likely to survive and flourish include:
- Applications where no other IR technology is effective (e.g. indexing of still images)
- Applications with an income to pay the costs of indexing and thesaurus maintenance (e.g. profitable bibliographic databases)
- Applications with new benefits to spread the costs over more outcomes (e.g. via Linked Data and/or mapping services)
- Enhanced implementation behind the scenes, so that users get the benefits without the discomforts of look-up (e.g. with automatic–aided indexing)
- Evolved or hybrid KOSs, with new characteristics that are now in demand (e.g. by incorporation of domain-specific relationships)
Examples of developments like these may be found in the special issue of Knowledge Organization (2016) mentioned above, and in Shiri (2012).
Simultaneously as true thesauri still thrive in the types of application just listed, a parallel future may lie in their gradual transformation under the banner taxonomy. This term, long applied to the practice and science of classification and especially the Linnaean classification of biological organisms, has been widely applied since the 1990s to a variety of KOSs found in electronic media. Applications include corporate intranets, online retail sales outlets, digital libraries, public sector advice websites, as well as displacement of the thesaurus in some of its traditional occupations. White (2016) points to the value of KO tools and techniques in some of these contexts.
There's still little uniformity among the "taxonomies" being developed for such applications, which may be simple heading lists, or may be complex hybrids that combine features from thesauri, traditional classification schemes, faceted schemes, ontologies and other types of KOS. In comparison with the widespread adoption of web search engines, their value is barely recognized. But there certainly is a very large need and opportunity for the principles of knowledge organization to be applied towards helping millions of workers in the knowledge society to find information resources of all kinds. The names we shall find for the emerging hybrid vocabularies are hard to predict, but we can safely say that the thesaurus will pass some of its genes into new tools for searching the cyberworld to come.
8. Further reading
(a) Useful registers of thesauri (among other types of KOS) may be found in the Basel Register of Thesauri, Ontologies & Classifications at bartoc.org and the Taxonomy Warehouse at taxonomywarehouse.com. The latter site also lists relevant events, blogs, publishers and links to some associated products such as software.
(b) Two guides to thesaurus construction are recommended:
- Aitchison, Gilchrist and Bawden (2000). Thesaurus construction: a practical manual.
- Broughton (2006). Essential thesaurus construction.
The first of these also carries an extensive bibliography. Both guides draw heavily on the then current national and international standards for thesauri: ISO 2788, ISO 5964, BS8723 and ANSI/NISO Z39.19 (of which the first three have since been withdrawn, superseded by ISO 25964).
(c) Specialist software is needed for thesaurus construction and maintenance. While ISO 25964-1 and ANSI/NISO Z39.19 both advise on the functionality required, see also the following article and its list of references:
- Will (2010). Thesaurus Management Software.
(d) A special issue of Cataloging & Classification Quarterly (Roe and Thomas 2004) was devoted to "The thesaurus: review, renaissance and revision", in which all the articles have useful reference lists. Contents include:
- Aitchison and Dextre Clarke (2004). The thesaurus: a historical viewpoint, with a look to the future.
- Greenberg (2004). User comprehension and searching with information retrieval thesauri.
- Johnson (2004). Distributed thesaurus web services.
- Landry (2004). Multilingual subject access: the linking approach of MACS.
- Lykke Nielsen (2004). Thesaurus construction: key issues and selected readings.
- Owens and Cochrane (2004). Thesaurus evaluation.
- Riesland (2004). Tools of the Trade: Vocabulary Management Software.
- Shearer (2004). A practical exercise in building a Thesaurus.
- Thomas (2004). Teach yourself thesaurus: exercises, readings, resources.
- Will (2004). Thesaurus consultancy.
(e) A special issue of Knowledge Organization (2016, 43 no. 3) was devoted to a continuation of the ISKO-UK debate "This house believes that the traditional thesaurus has no place in modern information retrieval". All the articles have useful reference lists. Contents include:
- Dextre Clarke (2016). Origins and trajectory of the long thesaurus debate.
- Dextre Clarke and Vernau (2016). Guest editorial: the thesaurus debate continues.
- Dextre Clarke and Vernau (2016). Questions and answers on current developments inspired by the thesaurus tradition.
- Garcia-Marco (2016). Enhancing the visibility and relevance of thesauri in the Web: searching for a hub in the linked data environment.
- Hjørland (2016). Does the traditional thesaurus have a place in modern information retrieval?
- Kempf and Neubert (2016). The role of thesauri in an open Web: a case study of the STW Thesaurus for Economics.
- MacFarlane (2016). Knowledge Organisation and its role in multimedia information retrieval.
- Tudhope and Binding (2016). Still quite popular after all those years: the continued relevance of the information retrieval thesaurus.
- White (2016). The value of taxonomies, thesauri and metadata in enterprise search.
(f) The interest group NKOS (Networked Knowledge Organization Systems/Services/Structures) runs projects and activities enabling all sorts of KOS as networked interactive information services, especially through the Internet. On its website at nkos.slis.kent.edu are links to many relevant publications and the proceedings of past events. The presentations from the NKOS workshops in USA and Europe are especially helpful in pointing to the future of thesauri and other KOSs. For an overview, see Tudhope and Lykke Nielsen (2006).
Endnotes
1. Information retrieval is used here broadly to mean "the activity of obtaining information resources relevant to an information need from one or more collections of information resources" (definition adapted from Wikipedia). It is not limited to use in systems held on computer.
2. As explained on the W3C (World Wide Web Consortium) website, "SKOS [Simple Knowledge Organization Systems] is an area of work developing specifications and standards to support the use of knowledge organization systems (KOS) such as thesauri, classification schemes, subject heading systems and taxonomies within the framework of the Semantic Web". A key product of this programme is the SKOS Simple Knowledge Organization System Reference (Miles and Bechhofer 2009), a common data model for sharing and linking knowledge organization systems via the Web. Development work on this specification took place around the same time as the development of BS 8723 and ISO 25964, with regular communication between the corresponding teams, so that a high degree of compatibility was achieved. The main difference between them can be summarized as follows: While ISO 25964-1 serves as a standard for construction of thesauri, SKOS is a standard for publishing thesauri and other types of KOS on the Web. Likewise ISO 25964-2 recommends the sort of mappings that can be established between one KOS and another; SKOS presents a way of expressing these when published to the Web.
The data models of these two standards are not identical, because ISO 25964 must provide for the needs of all sorts of thesauri (whether for Web use or for other applications) while SKOS must provide for all sorts of KOS (including classification schemes and many others that do not comply with ISO 25964). Good alignment between the two made possible a set of correspondences <ISO25964-SKOSXL-MADS-2013-12-11.pdf> between components of the data models, developed by the same teams of authors. Where the basic SKOS data model lacked a construct corresponding to a feature of the ISO 25964 model, the SKOS-XL <www.w3.org/TR/skos-reference/skos-xl.html> model was used, supplemented by additional proposals where necessary. Care was taken to avoid incompatibility with another project to align SKOS with MADS <www.loc.gov/standards/mads/>. Based on the documented correspondence table, an RDF schema that provides a machine-readable version for these mappings as well as for the elements from the ISO 25964 model was developed and made available at http://purl.org/iso25964/skos-thes. At the time of writing (July 2017) this latter site is unavailable but work is in hand to restore it. More background on all the above developments is provided at www.niso.org/schemas/iso25964/#skos.
It should be noted that exploitation of these interoperability standards and opportunities demands skill and attention to detail. Some practical examples and cautionary tales are provided in De Smedt (2012) and Lindenthal (2012).
3. The American standard ANSI/NISO Z39.19 and the International standard ISO 25964 are broadly aligned. Here are some key points of similarity or difference:
- The latest version of Z39.19 is a single document, issued in 2005 and reaffirmed in 2010; whereas ISO 25964 is a two-part standard, of which the first part (ISO 25964-1) was issued in 2011 and confirmed in 2017 while the second (ISO 25964-2) was issued in 2013.
- The scope of Z39.19 is broadly comparable with that of ISO 25964-1, but Z39.19 covers several types of monolingual controlled vocabulary — lists of controlled terms, synonym rings, taxonomies and thesauri — while ISO 25964-1 deals only with thesauri, both monolingual and multilingual.
- ISO 25964-1 provides a data model but Z39.19 does not.
- The whole of ISO 25964-2 (99 pages) deals with interoperability between thesauri and other types of KOS, including classification schemes, taxonomies, subject heading schemes, ontologies, terminologies, name authority lists, synonym rings. The treatment of interoperability in Z39.19 is contained in one clause of eight pages (plus a five-page appendix), in which multilingual thesauri are treated as a special case of interoperability.
- Z39.19 may be downloaded free of charge from the NISO website, whereas each part of ISO 25964 currently (2017) costs 198 Swiss francs, from the ISO store.
In view of the relatively wider scope of ISO 25964 in respect of thesauri, including in-depth treatment of interoperability and provision of a data model, it has been referenced more often than Z39.19 in this article.
References
Aitchison, Jean. 1977. UNESCO Thesaurus. Paris: UNESCO.
Aitchison, Jean. 1996. International thesaurus of refugee terms. 2nd ed. New York and Geneva: United Nations High Commissioner for Refugees.
Aitchison, Jean and Stella Dextre Clarke. 2004. The thesaurus: a historical viewpoint, with a look to the future. Cataloging & Classification Quarterly 37, no. 3/4: 5-21.
Aitchison, Jean and Alan Gilchrist. 1972. Thesaurus construction: a practical manual. 1st ed. London: Aslib.
Aitchison, Jean, Alan Gilchrist and David Bawden. 2000. Thesaurus construction and use: a practical manual. 4th ed. London: Aslib.
Aitchison, Jean, Alan Gomersall and Ralph Ireland. 1969. Thesaurofacet: a thesaurus and faceted classification for engineering and related subjects. Whetstone, Leicester: English Electric Company, Ltd.
Alexiev, Vladimir, Antoine Isaac and Jutta Lindenthal. 2014. On Compositionality of ISO 25964 Hierarchical Relationships (BTG, BTP, BTI). 13th European Networked Knowledge Organization Systems (NKOS) Workshop held during the DL2014 Conference in London. https://at-web1.comp.glam.ac.uk/pages/research/hypermedia/nkos/nkos2014/content/NKOS2014-abstract-alexiev-isaac-lindenthal.pdf
American Institute of Chemical Engineers. 1961. Chemical Engineering Thesaurus: a wordbook for use with the concept coordination system of information storage and retrieval. New York: American Institute of Chemical Engineers.
American National Standards Institute. 1974. American National Standard Guidelines for thesaurus structure, construction and use. ANSI Z39.19-1974. American National Standards Institute, New York.
Andrade, Julietti de and Marilda Lopes Ginez de Lara. 2016. Interoperability and mapping between Knowledge Organization Systems: Metathesaurus - Unified Medical Language System of the National Library of Medicine. Knowledge Organization 43, no. 2: 107-12.
Armed Services Technical Information Agency. 1960. Thesaurus of ASTIA Descriptors. Arlington, VA: Armed Services Technical Information Agency.
Baca, Murtha and Melissa Gill. 2015. Encoding multilingual knowledge systems in the digital age: the Getty vocabularies. Knowledge Organization 42, no. 4: 232-43.
Berners-Lee, Tim. 2006. "Linked Data." Web page. Available at www.w3.org/DesignIssues/LinkedData.html.
Biswas, Subal C and Fred Smith. 1989. Classed thesauri in indexing and retrieval: a literature review and critical evaluation of online alphabetic classaurus. Library and Information Science Research 11, no. 2: 109-41.
Boteram, Felix, Winfried Goedert and Jessica Hubrich, Eds. 2011. Concepts in Context: Proceedings of the Cologne Conference on Interoperability and Semantics in Knowledge Organization. Wuerzburg, Germany: Ergon Verlag.
British Standards Institution. 1981. BSI ROOT Thesaurus. 1st ed. Milton Keynes, England: British Standards Institution.
Broughton, Vanda. 2006a. Essential thesaurus construction. London: Facet publishing.
Broughton, Vanda. 2006b. The need for a faceted classification as the basis of all methods of information retrieval. Aslib Proceedings 58, no. 1/2: 49-72.
Caplan, Priscilla Louise. 1978. Thesaurus-based automatic indexing: a study of indexing failure. Chapel Hill, North Carolina University.
Caracciolo, Caterina and Johannes Keizer. 2014. What KOS can do, with the proper tools available. About AGROVOC, edited in VocBench and used in the AGRIS web application. Knowledge Organization - making a difference: ISKO UK biennial conference. http://www.iskouk.org/sites/default/files/CaraccioloSlidesISKO-UK2015.pdf
De Keyser, Pierre. 2012. Introduction to subject headings and thesauri. Indexing: from thesauri to the Semantic Web. Pierre De Keyser, 1-37. Chandos Publishing (Oxford), Limited.
De Smedt, Johan. 2012. Exchanging ISO 25964-1 thesauri data using RDF, SKOS and SKOS-XL. Presentation in 11th European Networked Knowledge Organization Systems (NKOS) Workshop, Sept 2012. https://at-web1.comp.glam.ac.uk/pages/research/hypermedia/nkos/nkos2012/presentations/ISO25964-mapping-to-SKOS-XL_TPDL-2012-09-27v6.pdf.
Dextre Clarke, Stella G. 2001. Organising access to information by subject. Handbook of information management (previously Handbook of special librarianship and information work). 8th edition ed., Editor Alison Scammell. London: Aslib, 72-110.
Dextre Clarke, Stella G. 2008. The last 50 years of knowledge organization: a journey through my personal archives. Journal of Information Science 34, no. 4: 427-37.
Dextre Clarke, Stella G. 2011a. In Pursuit of Interoperability: Can We Standardize Mapping Types? Concepts in Context: Proceedings of the Cologne Conference on Interoperability and Semantics in Knowledge Organization, eds Felix Boteram, Winfried Goedert and Jessica Hubrich. Wuerzburg, Germany: Ergon Verlag, 91-109.
Dextre Clarke, Stella G. 2011b. Knowledge Organization System Standards. Encyclopedia of Library and Information Science. 3rd ed., Taylor and Francis. http://www.tandfonline.com/doi/abs/10.1081/E-ELIS3-120044538.
Dextre Clarke, Stella G. 2016. Origins and trajectory of the long thesaurus debate. Knowledge Organization 43, no. 3: 138-44.
Dextre Clarke, Stella G. and Marcia Lei Zeng. 2012. From ISO 2788 to ISO 25964: the evolution of thesaurus standards towards interoperability and data modeling. Information Standards Quarterly, 24, no. 1 (Winter): 20-26. http://www.niso.org/publications/isq/2012/v24no1/clarke/. DOI 10.3789/isqv24n1.2012.04.
Doerr, Martin. 2000. Semantic Problems of Thesaurus Mapping. Journal of Digital Information 1, no. 8. http://jodi.ecs.soton.ac.uk/Articles/v01/i08/Doerr/.
Elsevier Science. EMTREE : The life science thesaurus. Amsterdam: Elsevier Science.
Fast, Karl, Leise, Fred and Steckel, Mike. 2002. "Controlled vocabularies: a glosso-thesaurus". Web page [accessed February 2017]. Available at http://boxesandarrows.com/controlled-vocabularies-a-glosso-thesaurus/.
Foskett, Douglas J. 1980. Thesaurus. Encyclopaedia of library and information science, eds. A. Kent, H. Lancour and J.E. Daily, 416-62. Vol. 30. New York: Marcel Dekker.
Garcia-Marco, Francisco Javier. 2016. Enhancing the visibility and relevance of thesauri in the Web: searching for a hub in the linked data environment. Knowledge Organization 43, no. 3: 193-202.
Garshol, Lars Marius. 2004. "Metadata? Thesauri? Taxonomies? Topic Maps! Making sense of it all." Web page [accessed June 2017]. Available at http://www.ontopia.net/topicmaps/materials/tm-vs-thesauri.html. Also published in Journal of Information Science Vol 30(4), 2004, pp378-391.
Getty Art History Information Program. 1994. Art & Architecture Thesaurus. 2nd ed. Oxford and New York: Oxford University Press.
Gilchrist, Alan. 1971. The thesaurus in retrieval. London: Aslib.
Greenberg, Jane. 2004. User comprehension and searching with information retrieval thesauri. Cataloging & Classification Quarterly 37, no. 3/4: 103-20.
Hjørland, Birger. 2015. Classical databases and knowledge organization: a case for Boolean retrieval and human decision-making during searches. Journal of the Association for Information Science and Technology 66, no. 8: 1559-75.
Hjørland, Birger. 2016. Does the traditional thesaurus have a place in modern information retrieval? Knowledge Organization 43, no. 3: 145-59.
Hodge, Gail. 2000. Systems of Knowledge Organization for Digital Libraries: beyond traditional authority files. Washington DC: Digital Library Federation. Also available at: http://www.clir.org/pubs/reports/pub91/contents.html
Hood, Martha W. and Christine Ebermann. 1990. Reconciling the CAB Thesaurus and AGROVOC. IAALD Quarterly Bulletin 35, no. 3: 181-85.
Hoppe, Stephan. 1996. The UMLS: a model for knowledge integration in a subject field. In: Compatibility and Integration of Order Systems: Research Seminar Proceedings of the TIP/ISKO Meeting, eds. Ingetraut Dahlberg and Krystyna Siwek. Warsaw: International Society for Knowledge Organization, 97-110.
Horsnell, Verina. 1975. The Intermediate Lexicon: an aid to international co-operation. Aslib Proceedings 27, no. 2: 57-66.
Hudon, Michele. 2001. Relationships in multilingual thesauri. Relationships in the organization of knowledge, eds. Carol A. Bean and Rebecca Green. Dordrecht: Kluwer, 67-80.
International Organization for Standardization. 1974. ISO 2788-1974. Documentation - Guidelines for the establishment and development of monolingual thesauri. 1st ed. Geneva: International Organization for Standardization.
International Organization for Standardization. 1985. ISO 5964-1985. Documentation - Guidelines for the establishment and development of multilingual thesauri. Geneva: International Organization for Standardization.
International Organization for Standardization. 1996. ISO 999:1996 Information and documentation - Guidelines for the content, organization and presentation of indexes. Geneva: International Organization for Standardization.
International Organization for Standardization. 2011. ISO 25964-1: Information and documentation - thesauri and interoperability with other vocabularies - Part 1: Thesauri for information retrieval. Geneva: International Organization for Standardization.
International Organization for Standardization. 2013. ISO 25964-2: Information and documentation - thesauri and interoperability with other vocabularies - Part 2: Interoperability with other vocabularies. Geneva: International Organization for Standardization.
Isaac, Antoine and Thomas Baker. 2015. Linked Data Practice at Different Levels of Semantic Precision: The Perspective of Libraries, Archives and Museums. ASIS&T Bulletin. http://www.asis.org/Bulletin/Apr-15/AprMay15_Isaac_Baker.html
Joyce, T. and R.M. Needham. 1958. The thesaurus approach to information retrieval. American Documentation 9: 192-97.
Keen, E. Michael. 1973. The Aberystwyth index languages test. Journal of Documentation 29, no. 1: 1-35.
Kempf, Andreas Oscar and Joachim Neubert. 2016. The role of thesauri in an open Web: a case study of the STW Thesaurus for Economics. Knowledge Organization 43, no. 3: 160-173.
Kless, Daniel, Simon Milton and Edmund Kazmierczak. 2012. Relationships and relata in ontologies and thesauri: Differences and similarities. Applied Ontology 7, no. 4: 401-28.
Knapp, Sara D. 1993. The contemporary thesaurus of social science terms and synonyms. A guide for natural language computer searching. Arizona: Oryx.
Krooks D A and Lancaster F W. 1993. The evolution of guidelines for thesaurus construction. Libri 43, no. 4: 326-42.
Lancaster, F W. 1972. Vocabulary control for information retrieval. Washington, D.C.: Information Resources Press.
Lancaster, F W. 1998. Indexing and abstracting in theory and practice. London: LA Publishing.
Lindenthal, Jutta. 2012. Ambiguities in representing thesauri using extended SKOS – examples from real life. Presentation in 11th European Networked Knowledge Organization Systems (NKOS) Workshop, Sept 2012. https://at-web1.comp.glam.ac.uk/pages/research/hypermedia/nkos/nkos2012/presentations/TPDL2012_NKOS_Ambiguities_R1.pdf.
Leatherdale, Donald. 1982. AGROVOC. 1st ed. Collaborators G Eric Tidbury and Roy Mack. Rome, Italy: Food and Agriculture Organization of the United Nations and Commission of the European Communities.
Lopez-Huertas, M. J. 1997. Thesaurus structure design: a conceptual approach for improved interaction. Journal of Documentation 53, no. 2: 139-77.
Lykke Nielsen, Marianne. 2001. A framework for work task based thesaurus design. Journal of Documentation 57, no. 6: 774-97.
Lykke Nielsen, Marianne. 2004. Thesaurus construction: key issues and selected readings. Cataloging & Classification Quarterly 37, no. 3/4: 57-74.
MacFarlane, Andrew. 2016. Knowledge Organisation and its role in multimedia information retrieval. Knowledge Organization 43, no. 3: 180-183.
Mader, Christian and Haslhofer, Bernard. 2015. Quality criteria for controlled web vocabularies" Web page. Available at https://www.researchgate.net/publication/267832936_Quality_Criteria_for_Controlled_Web_Vocabularies.
Mayr, Philipp and Vivien Petras. 2008. Building a terminology network for search: the KoMoHe project. Metadata for Semantic and Social Applications. Proceedings of the International Conference on Dublin Core and Metadata Applications, eds. Jane Greenberg and Wolfgang Klas. Dublin Core Metadata Initiative and Universitaetsverlag Goettingen, 177-82.
Miles, Alistair. 2006. Retrieval and the Semantic Web: incorporating A Theory of Retrieval Using Structured Vocabularies. Oxford Brookes University. https://www.researchgate.net/publication/ 30410464_Retrieval_and_the_Semantic_Web_incorporating_A_Theory_of_Retrieval_Using_Structured_Vocabularies
Miles, Alistair and Bechhofer, Sean, Editors. 2009. SKOS Simple Knowledge Organization System Reference. W3C Recommendation. Web page. Available at http://www.w3.org/TR/skos-reference.
National Information Standards Organization 2005. Guidelines for the construction, format, and management of monolingual controlled vocabularies. ANSI/NISO Z39.19-2005 (R2010). National Information Standards Organization, Maryland, USA.
National Library of Medicine. Medical Subject Headings (MeSH). Annually updated in print until 2007; thereafter maintained online only. Bethesda, Maryland: National Library of Medicine.
Office of Naval Research. 1967. Thesaurus of engineering and scientific terms (TEST). New York: Engineers Joint Council and US Department of Defense.
Owens, Lesley Ann and Pauline Atherton Cochrane. 2004. Thesaurus evaluation. Cataloging & Classification Quarterly 37, no. 3/4: 87-102.
Riesthuis, Gerhard JA and Steffi Bliedung. 1991. Thesaurification of the UDC. Tools for knowledge organization and the human interface. Proceedings of the 1st International ISKO Conference, Editor Robert Fugmann. Frankfurt/Main: Indeks Verlag, Vol 2, 109-17.
Roberts, N. 1984. The pre-history of the information retrieval thesaurus. Journal of Documentation 40, no. 4: 271-85.
Roe, Sandra K. and Alan R. Thomas, eds. 2004. Cataloging & Classification Quarterly. Vol. 37 (3/4). Haworth.
Roget, Peter. 1952. Everyman's Thesaurus of English words and phrases. Reviser D.C. Browning. London: J.M. Dent & Sons.
Rolland-Thomas, P. 1993. Thesaural codes: an appraisal of their use in the Library of Congress Subject Headings. Cataloging & Classification Quarterly 16, no. 2: 71-91.
Sharp, J. R. 1967. Information retrieval. Handbook of special librarianship and information work. 3rd ed., editor Wilfred Ashworth, 141-232. London: Aslib.
Shiri, Ali. 2012. Powering search: the role of thesauri in new information environments. Medford, New Jersey: Information Today, Inc.
Shiri, Ali Asghar, Crawford Revie and Gobinda Chowdhury. 2002. Thesaurus-enhanced search interfaces. Journal of Information Science 28, no. 2: 111-22.
Smiraglia, Richard, ed. 2016. Knowledge Organization. Vol. 43 (3). Ergon Verlag.
Soergel, Dagobert. 1974. Indexing languages and thesauri: construction and maintenance. Los Angeles, California: Melville.
Soergel, Dagobert. 1994. Indexing and retrieval performance: the logical evidence. Journal of the American Society for Information Science 45, no. 8: 589-99.
Soergel, Dagobert 2014. Knowledge organization for learning. In: Knowledge organization in the 21st Century: Between historical patterns and future prospects. Proceedings of the Thirteenth International ISKO Conference. Ergon Verlag. 22-32.
Spero, Simon E. 2008. LCSH is to Thesaurus as Doorbell is to Mammal: Visualizing Structural Problems in the Library of Congress Subject Headings. DCMI International Conference on Dublin Core and Metadata Applications. http://dcpapers.dublincore.org/pubs/article/view/937.
Spero, Simon E. 2012. What, if anything, is a subdivision? in: Facets of Knowledge Organization: Proceedings of the ISKO UK Second Biennial Conference, editors Alan Gilchrist and Judi Vernau. Bingley, UK: Emerald Group Publishing Ltd. 69-83.
Svenonius, Elaine. 1986. Unanswered questions in the design of controlled vocabularies. Journal of the American Society for Information Science 37, no. 5: 331-40.
Tudhope, Douglas and Ceri Binding. 2016. Still quite popular after all those years: the continued relevance of the information retrieval thesaurus. Knowledge Organization 43, no. 3: 174-79.
Tudhope, Douglas, Traugott Koch and Rachel Heery. 2006. Terminology Services and Technology: JISC state of the art review. Available at: http://www.ukoln.ac.uk/terminology/JISC-review2006.html. JISC.
Tudhope, Douglas and Marianne Lykke Nielsen. 2006. Introduction to Knowledge Systems and Services. New Review of Hypermedia and Multimedia 12, no. 1: 3-9.
Viet, Jean. 1972. Macrothesaurus for information processing in the field of economic and social development. 1st ed. Paris: OECD Development Centre.
Vizine-Goetz, Diane, Carol Hickey, Andrew Houghton and Roger Thompson. Vocabulary Mapping for Terminology Services. Journal of Digital Information 4, no. 4 (2004): Article No. 272.
Wellisch, Hans H. 1995. Indexing from A to Z. New York, Dublin: H W Wilson.
White, Martin. 2016. The value of taxonomies, thesauri and metadata in enterprise search. Knowledge Organization 43, no. 3: 184-92.
Will, Leonard. 2010. Thesaurus Management Software. Encyclopedia of Library and Information Sciences. Third ed., 5238-46. Taylor and Francis. http://www.tandfonline.com/doi/abs/10.1081/E-ELIS3-120044528.
Will, Leonard. 2012. The ISO 25964 data model for the structure of an information retrieval thesaurus. Bulletin of the American Society for Information Science and Technology 38, no. 4. https://asistdl.onlinelibrary.wiley.com/doi/epdf/10.1002/bult.2012.1720380413. DOI 10.1002/bult.2012.1720380413.
Working Group on Guidelines for Multilingual Thesauri of IFLA Classification and Indexing Section chaired by Gerhard J. A. Riesthuis and Patrice Landry. 2009. "Guidelines for multilingual thesauri". Web page. Available at http://archive.ifla.org/VII/s29/pubs/Profrep115.pdf.
Zeng, Marcia Lei. 2008. Knowledge Organization Systems (KOS). Knowledge Organization 35, no. 2-3: 160-182.
Zeng, Marcia Lei and Lois Mai Chan. 2004. Trends and issues in establishing interoperability among Knowledge Organization Systems. Journal of the American Society for Information Science and Technology 55, no. 5: 377-95.
Visited times since 2019-03-07 (one year and a half after first publication).
Version 1.2 (= 1.0 plus additional references and minor corrections); version 1.0 published 2017-09-07, this version 2019-03-07, last edited 2024-12-17
Article category:
KOS KindsThis article (version 1.0) is also published in Knowledge Organization. How to cite it: Dextre Clarke, Stella G. 2019. "The Information Retrieval Thesaurus". Knowledge Organization 46, no. 6: 439-59. Also available in ISKO Encyclopedia of Knowledge Organization, eds. Birger Hjørland and Claudio Gnoli, https://www.isko.org/cyclo/thesaurus.
©2017 ISKO. All rights reserved.